

首充送50%
续费低至5折
AWS CDN 1折购
免费代充值
免费选购指南
免费协助迁移

2023-07-31
SaaS 开发商在利用 LLM 实现智能客服系统时通常会发现,客服系统的负载在不同时段起伏很大。尤其在促销、市场活动、特殊事件等情况下很难准确预估用量,更难根据需求准确地预置系统资源。在这种情况下,使用 Lambda 来构建该系统,在支持并发的前提下实现成本节省可能成为很多开发团队考虑的方向。但在实施之前,我们必须明确如下几个问题:
本博客带着这些实际问题对 Lambda 实现智能客户的方案进行了 POC 测试,并给出了可落地的代码参考。
本博客我们将通过描述智能客服 SaaS 平台的通用需求展示 SaaS 软件供应商如何向企业客户提供 SaaS 类的智能客服服务。企业客户订阅该服务后,就可通过 SaaS 平台提供的 API 将智能客服嵌入自身系统中,快速构建企业自己的客服系统。
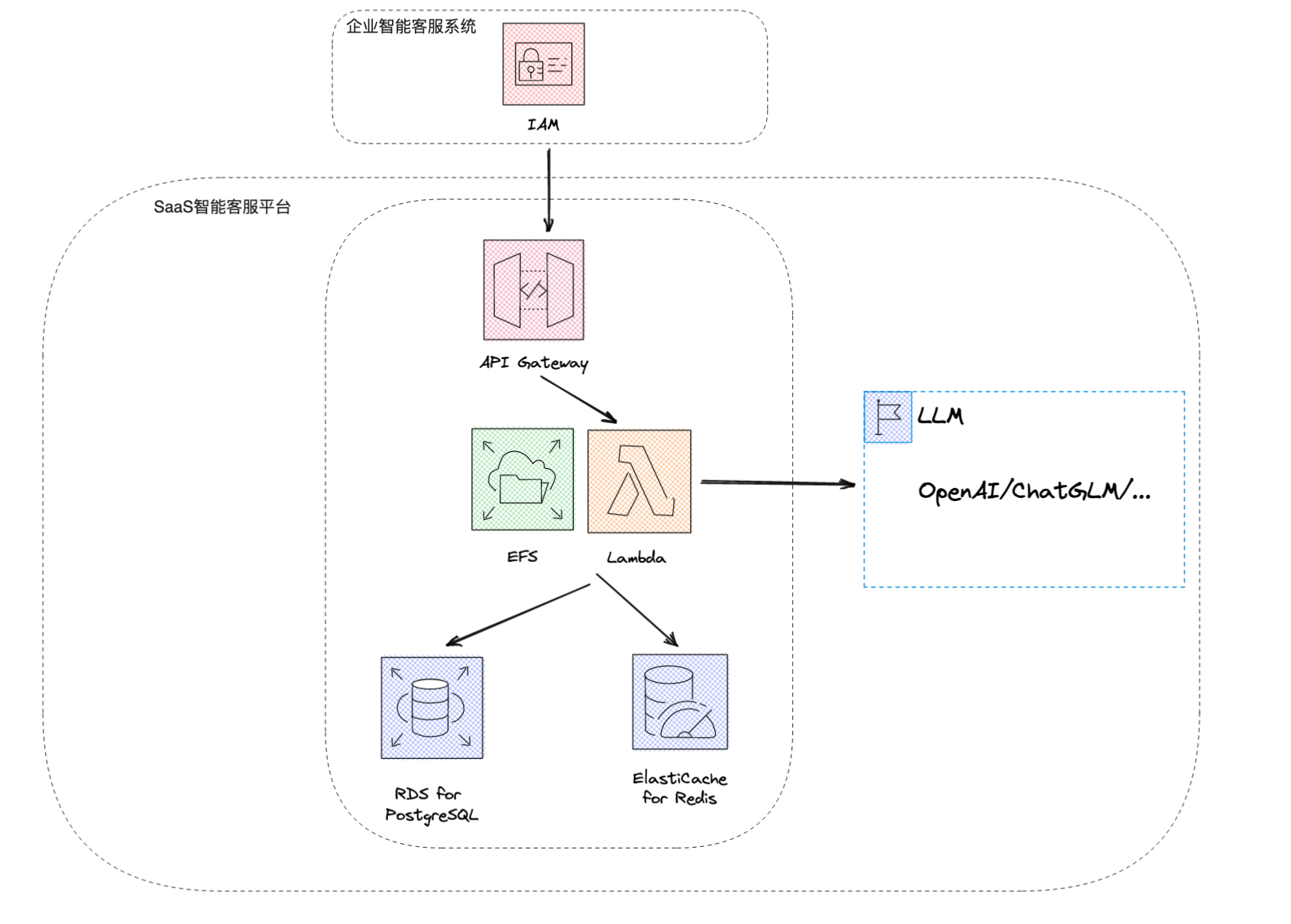
系统需求示意图如下:

下图展示了我们为该系统设计的 Lambda 架构:
目前基于 LLM 的智能客服实现已经有丰富的参考案例。但在 POC 过程中,我们发现用 Lambda 实现会碰到一些独特的问题,总结下来分享给大家。
使用 Python 脚本来完成基于 LLM 的私域问答需要较多的依赖包。在 EC2 中我们通过 pip install 直接安装即可,但 Lambda 中如何构建这些依赖包并在多个 Lambda 函数中共用是我们首先需要解决的问题。如下展示了实际的执行过程:
1. 使用 Docker 环境构建所需的完整依赖包,压缩上传至 S3
如果没有 Docker 环境则需自行安装。或者使用 AWS Cloud9,它提供了丰富的开发环境,您无需任何额外安装就可直接执行如下命令完成所有依赖包的打包、压缩、上传。
#构建 Docker 环境
docker pull public.ecr.aws/sam/build-python3.10:1.84.0-20230517004040
docker run -it -v $(pwd):/var/task public.ecr.aws/sam/build-python3.10:1.84.0-20230517004040
#将所有依赖包安装在 myzip1 目录下
mkdir myzip1
cd myzip1
pip install langchain openai tiktoken -t ./
pip install pgvector psycopg2-binary -t ./
pip install unstructured -t ./
pip install redis -t ./
#打包并上传至 S3
zip -r python.zip ./myzip
aws s3 cp python.zip s3://S3bucket/2. 为 Lambda 函数构建共享的依赖包
起初,我们试图用 Lambda Layer 完成共享依赖包的构建。因为 Lambda Layer 便于开发者分别管理函数代码和第三方依赖包,不仅可以减小函数代码的尺寸,加快部署速度,更可以在多个 Lambda 函数中共享依赖包,提升开发效率。
但实际操作时,当我们使用上述压缩包构建 Layer 时遇到如下报错:
Failed to create layer version: Unzipped size must be smaller than 262144000 bytes原因是该方案涉及的依赖包 zip 文件为 91M,解压后超过 400M,已经超过了 Lambda Layer 的上限大小。在 Lambda Limit 中要求每个 Lambda 函数加上 Layer 的总大小不能超过 250 MB(unzipped size) 。详见 AWS Lambda Limits https://docs.aws.amazon.com/lambda/latest/dg/limits.html
为解决这个问题,我们摒弃 Lambda Layer 方案,转而采用 EFS 构建 Lambda file system 来存储共享的依赖包。
Amazon EFS 是一个完全托管、弹性、可持久的共享文件系统,可按需扩展到 PB 级。Lambda 的 Amazon EFS 可以帮助我们实现 Lambda 间大型文件的跨函数调用和共享。并且 EFS 文件系统可与 Lambda 函数一起扩展,支持多达 25,000 个并发,完全满足智能问答场景需求。
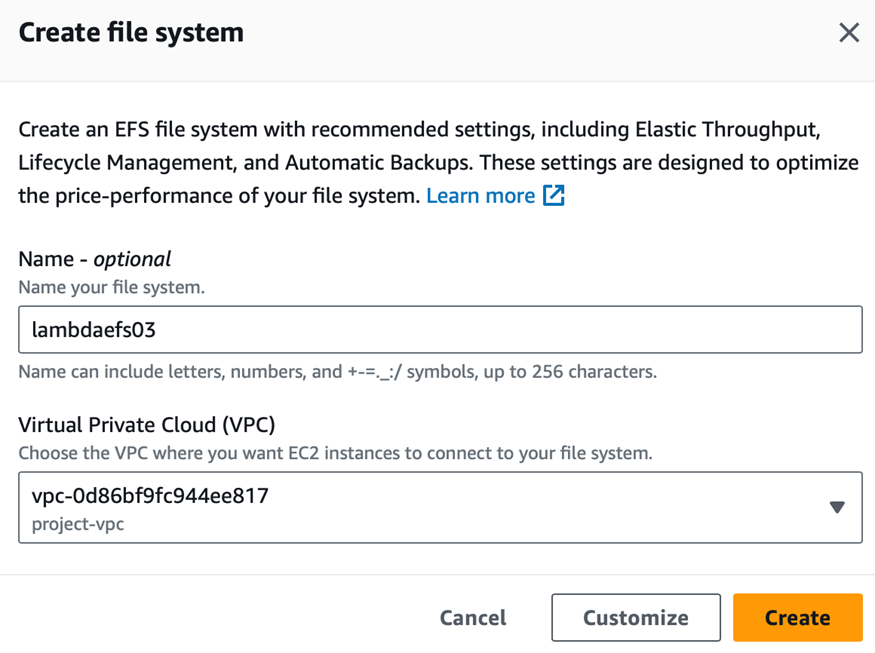
构建过程注意,创建 EFS 文件系统和 Lambda 函数必须驻留在同一个 VPC 中,因此需要将 Lambda 构建在 VPC 内。如下是创建 EFS 的过程参考:
-创建 VPC 下的 EFS
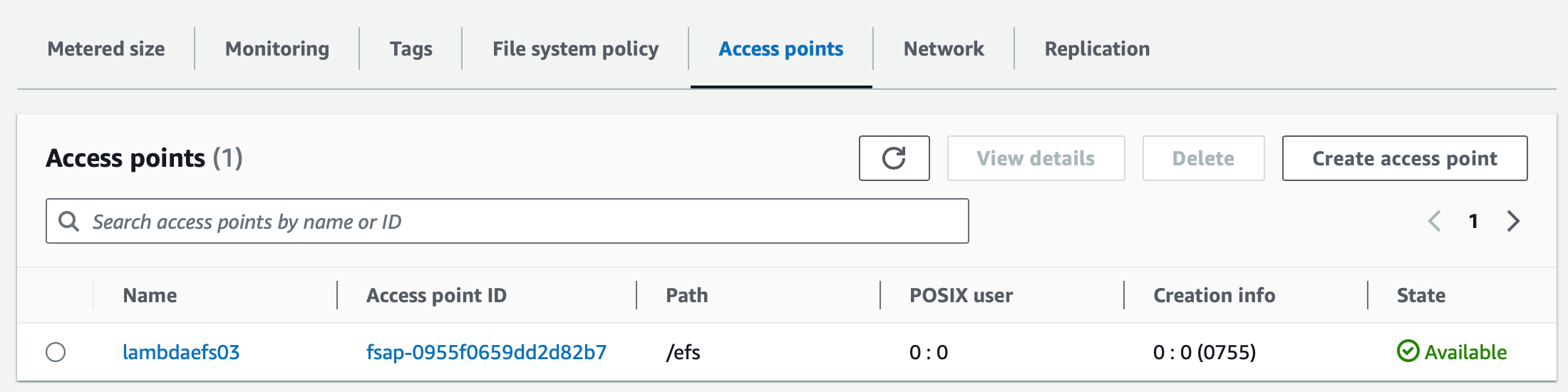
-创建 access point,并分配相应的权限:
如下为 root 用户分配 755 权限
-将 EFS 挂载到 EC2 上,并将依赖包从 S3 下载到 EFS,解压
sudo yum install -y amazon-efs-utils ##ec2 上 mount efs 需要安装
cd /mnt
mkdir efs
sudo mount -t efs -o tls fs-0288e213dad863836:/ efs ##将 EFS 挂载到/mnt/efs 目录
cd efs
aws s3 cp s3://S3bucket/python.zip ./
unzip python.zip
-将包含依赖包的 EFS 挂载到 Lambda
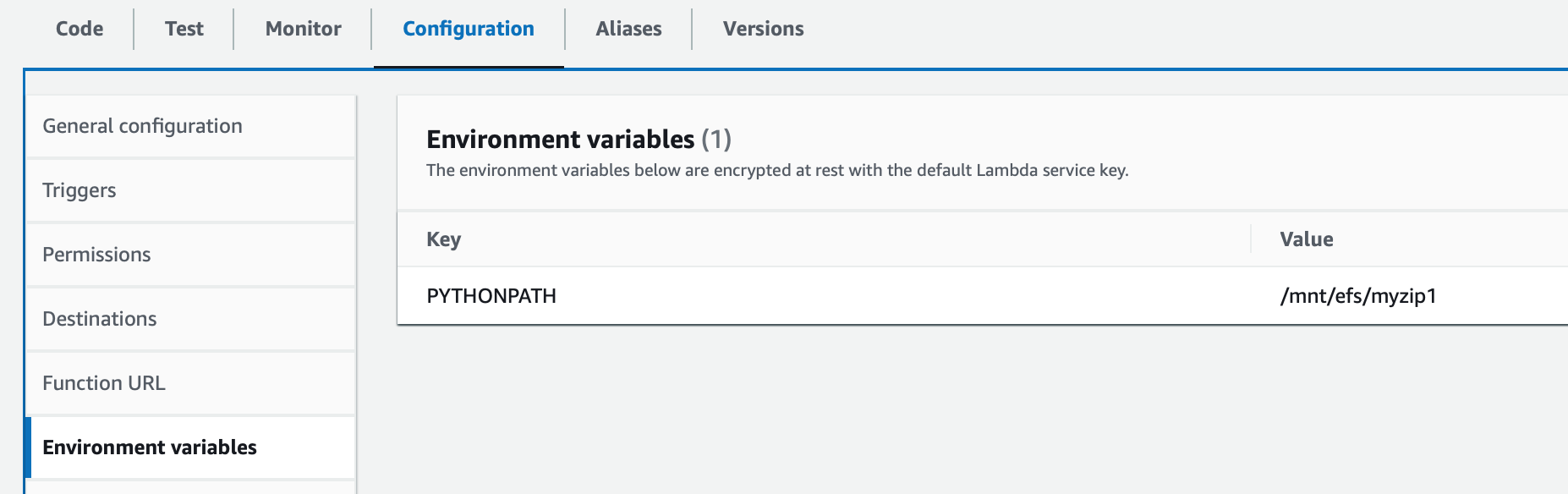
首先,保证 Lambda 构建在 EFS 所在的 VPC 中,然后在 Lambda 的 Configuration 中创建 EFS file system:

配置 Lambda 函数的 PYTHONPATH 环境变量指向该 EFS 目录,以便 Lambda 可以定位到所需依赖包。
其中/mnt/efs 为 EFS mount 到 Lambda 上的本地目录,myzip1 为依赖包所在子目录。
通过以上配置,Lambda 可以访问到本次 POC 所需的 LangChain,LLM,pgvector 等所有依赖包。
目前,Amazon RDS for PostgreSQL 已经支持 pgvector 扩展,可用于把来自机器学习模型的嵌入内容存储在 pg 库中,并执行高效的相似性搜索。POC 中,我们利用该特性存储了各个企业提供的私域文档,并放置在不同的 collection 来实现租户隔离。
首先连接 RDS for PG,创建 pgvector 扩展:
create extension vector;在 pgvector 中存储向量化的企业私域文档,Lambda 代码示例:
import json
import os
from langchain.llms import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
import boto3
def lambda_handler(event, context):
tenant = event['tenant']
filestr = '{}/{}'.format(tenant, event['file']) #在 S3 存储桶为每个 tenant 构建单独的目录,用于接受企业上传的私域文件
os.environ['OPENAI_API_KEY'] = 'sk-tMzxxxxxxOAd'
s3 = boto3.resource('s3')
#将文件下载到 Lambda 的/tmp 目录。Lambda 提供本地存储,最大允许 512MB,/tmp 目录为可写目录。
s3.Bucket('BUCKET-NAME').download_file(filestr, Filename='/tmp/{}'.format(event['file']))
filefullpath = '/tmp/' + event['file']
loader = TextLoader(filefullpath)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=70, chunk_overlap=0,separator='.')
texts = text_splitter.split_documents(documents)
#连接到 pgvector 向量库
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get('PGVECTOR_DRIVER', 'psycopg2'),
host=os.environ.get('PGVECTOR_HOST', 'openai03.ctxxxyw.us-east-1.rds.amazonaws.com'),
port=int(os.environ.get('PGVECTOR_PORT', '5432')),
database=os.environ.get('PGVECTOR_DATABASE', 'postgres'),
user=os.environ.get('PGVECTOR_USER', 'postgres'),
password=os.environ.get('PGVECTOR_PASSWORD', 'Passwordxxx'),)
#将切分后的文档向量化,并存入向量库
embeddings = OpenAIEmbeddings()
collection_name = tenant
db = PGVector.from_documents(
embedding=embeddings,
documents=texts,
##为每个企业定义独立的 collection,将向量化的私域文档分片存储至企业独立的 collection
collection_name=collection_name,
connection_string=CONNECTION_STRING,
)
return {
'statusCode': 200,
'body': json.dumps('Documents stored!')
}存储后可以看到 langchain 自动在 pg 库中创建了两张表:

Lambda 本身是无状态的。为了在回答用户提问时能够获得其会话历史,LangChain 通过与 DynamoDB、PostgreSQL、MongoDB 等多种数据存储集成,提供了丰富的 Memory 保存方式。下面我们以 RedisChatMessageHistory 类为例,展示使用 Redis 为每个用户保存会话历史的能力。
#会话历史使用 Redis 数据库进行保存,并通过 Session_id 对每个用户进行隔离。会话历史保留 3min。
#注意:会话历史保留过长,可能会超出 max token 的限额。
message_history = RedisChatMessageHistory(
url='redis://kingdee.oxxxr.ng.0001.use1.cache.amazonaws.com:6379/0', ttl=180, session_id=user_session
)
memory = ConversationBufferMemory(memory_key='chat_history',
chat_memory=message_history,
input_key='human_input',
return_messages=True)本次 POC 测试的特点是智能问答需要依赖多个输入,包括用户的当前问题,用户的历史会话,以及私域的文档,我们需要 LLM 根据这些输入做出相应的回答。根据这个需求梳理的代码如下:
import json
import os
from langchain.llms import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain.vectorstores.pgvector import DistanceStrategy
from langchain.memory import ConversationBufferMemory
from langchain import PromptTemplate
from langchain.chains import ConversationalRetrievalChain
from langchain.memory.chat_message_histories import RedisChatMessageHistory
from langchain.chains.question_answering import load_qa_chain
import base64
os.environ['OPENAI_API_KEY'] = 'sk-tMzrgxxxxxxRJOAd'
llm = OpenAI(temperature=0.9)
#准备好 pgvector 连接
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get('PGVECTOR_DRIVER', 'psycopg2'),
host=os.environ.get('PGVECTOR_HOST', 'openai03.ctfokeestnyw.us-east-1.rds.amazonaws.com'),
port=int(os.environ.get('PGVECTOR_PORT', '5432')),
database=os.environ.get('PGVECTOR_DATABASE', 'postgres'),
user=os.environ.get('PGVECTOR_USER', 'postgres'),
password=os.environ.get('PGVECTOR_PASSWORD', 'Password001'),)
#根据客户的实际场景组织 prompt 模版
template = '''You are a helpful hotel assistant,dedicated to answering customer questions.
Given the input documents and a question, create a final answer.
If you can not find answer from the documents, please answer questions according to your own knowledge. otherwise,answer the questions with your own knowledge.
{context}
{chat_history}
human_input: {human_input}
Chatbot:'''
prompt = PromptTemplate(
input_variables=['chat_history', 'human_input', 'context'], template=template
)
def lambda_handler(event, context):
print(event)
querystr = event['query']
tenant = event['tenant']
user_session = event['userid']
#根据租户信息定位到向量库中的 collection,实现租户私域文档的隔离
collection_name=tenant
store = PGVector(
connection_string=CONNECTION_STRING,
embedding_function=OpenAIEmbeddings(),
collection_name=collection_name,
distance_strategy=DistanceStrategy.COSINE
)
#根据用户的 id 获取到用户的历史会话信息
message_history = RedisChatMessageHistory(
url='redis://chatgpt.o2uckr.ng.0001.use1.cache.amazonaws.com:6379/0', ttl=180, session_id=user_session
)
memory = ConversationBufferMemory(memory_key='chat_history',
chat_memory=message_history,
input_key='human_input', return_messages=True)
#基于 memory 和 prompt 模版构建 qa chain
chain = load_qa_chain(
llm, chain_type='stuff', memory=memory, prompt=prompt
)
#在向量库中获得相关的文档片段
docs = store.similarity_search(querystr)
#获得基于会话历史和私域文档内容的智能应答。根据当前 prompt 的模版设定,如果私域文档中没有相关答案,则允许 LLM 做部分发挥,这种模版设定比较适合酒店、服务类行业等场景;如果需要严格按照私域文档内容进行应答,可在 prompt 中特别强调不要自行发挥。
replystr = chain({'input_documents': docs, 'human_input': querystr}, return_only_outputs=True)
return {
'statusCode': 200,
#'body': json.dumps(base64.b64decode(querystr).decode('utf-8'), ensure_ascii=False)
'body':replystr
}完成以上智能问答函数后,可以将 Lambda 集成 Amazon API Gateway,提供给企业访问。但 SaaS 平台将 API 开放给企业客户后,如何能保证 API 的安全访问,不被恶意调用呢?POC 中,我们使用了 Amazon API Gateway 基于 IAM 的安全控制策略,通过 IAM policy 来控制对 API 的操作权限:

{
'Version': '2012-10-17',
'Statement': [
{
'Sid': 'VisualEditor0',
'Effect': 'Allow',
'Action': 'execute-api:Invoke',
'Resource': 'arn:aws:execute-api:us-east-1:[AccountNo]:y13b6v7860/default/*/*'
}
]
}
当前场景下,企业客户对智能问答 API 的订阅是分层的(比如免费试用、标准级、白金级等等),SaaS 平台如何对处于不同层级的企业客户进行分层限流呢?
Amazon Rest API Gateway 提供了 Usage Plan 功能,允许 SaaS 平台为处于不同层级的订阅客户做 API 限流。通过 Usage plan,SaaS 平台可以为每个客户创建独立的 API Key,这些 API Key 用于标识每个企业客户,可以控制每个企业可以访问的一组服务和服务阶段(如测试、测试和生产等环境),并且可以为不同层级的访问创建 Usage plan,用于控制不同层级用户对 API 调用的请求率、突发容量和每天、每周或每月可以提出的请求数量。
如下图,我们分别创建了免费、青铜、白金三个使用计划。以 Free 级别为例,在该级别中:
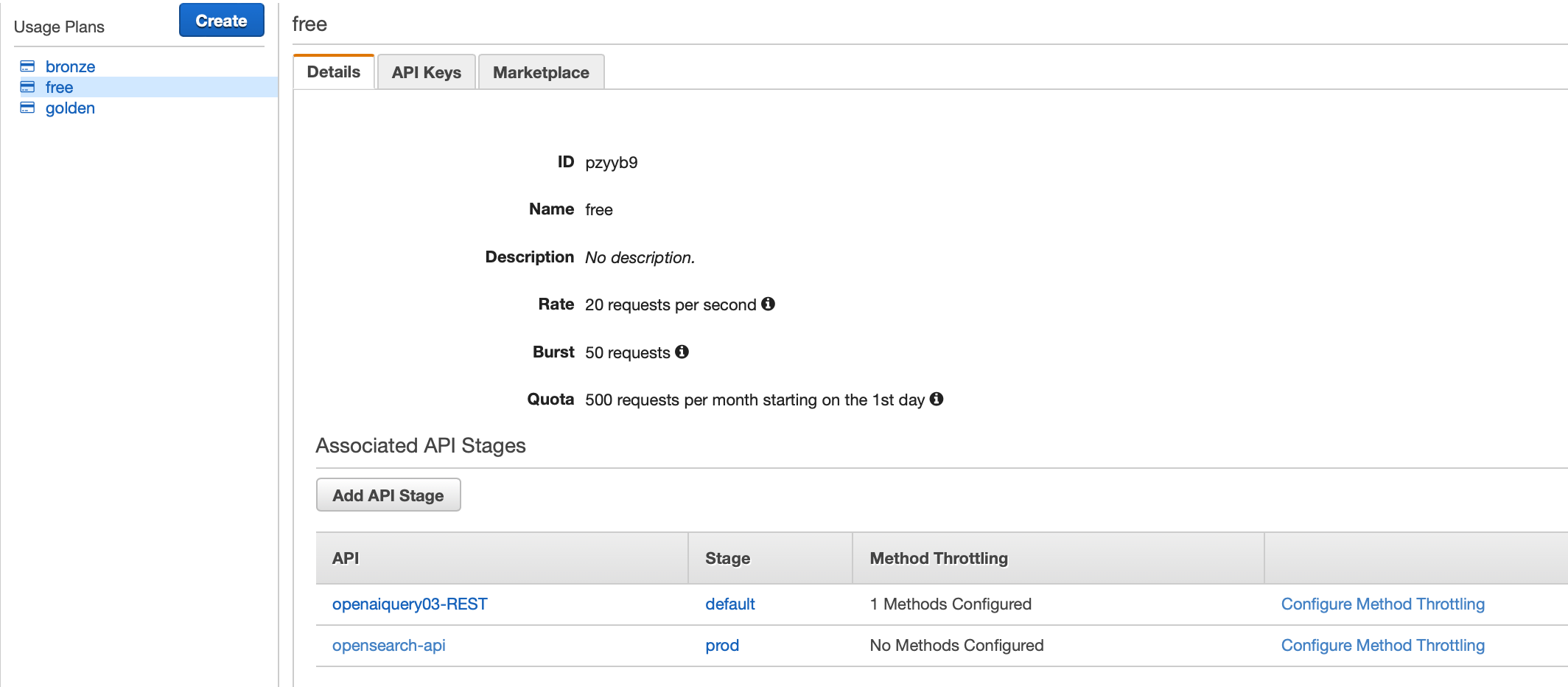


“Orange”API Key 对应的 ID 如下:
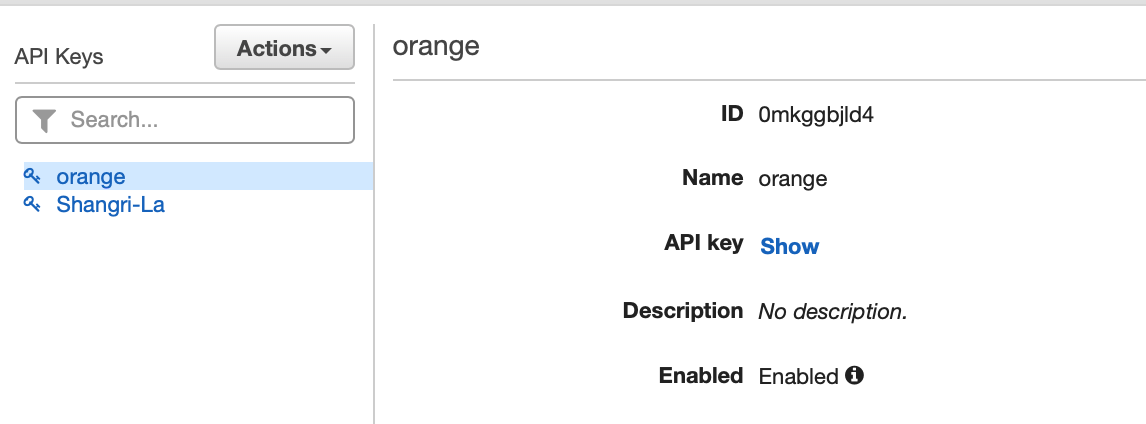
通过以上设置,“橘子酒店”的企业客户在调用 API 时必须在 header 中添加 x-api-key: 0mkggbjld4 才可访问相应资源,从而实现了 usage plan 中配置的限流。
通过以上测试,我们将 Lambda 与 LangChain 集成,并结合 Amazon RDS for PostgreSQL 和 ElastiCache Redis,实现了基于历史会话的企业私域问答服务。从 SaaS 开发商的实际需求出发,展示了如何在智能问答的 SaaS 平台中实现私域文档的租户隔离、用户历史会话隔离、以及 API 的安全管控和分层限流。
